Масштабування
Варіанти масштабування
- Підвищення характеристик серверу
- Розбити сервіси по різних серверах
- Кластерізація
- Node
- Redis
- PostgreSQL
- Kubernetes. Автоматизація масштабування
Важливо проводити моніторинг запитів БД, щоб виявляти повільні та не оптимізовані запити
1. Підвищення характеристик серверу
Можливо підвисити продуктивність одного серверу:
- Додати додаткову оперативну пам'ять для покращення продуктивності.
- Оновити процесор до більш потужного для збільшення обчислювальної потужності.
- Замінити жорсткий диск на швидкісний твердотілий накопичувач (SSD), що дозволить зменшити час доступу до даних та підвищити швидкість роботи серверу.
- Перевірити налаштування операційної системи та оптимізувати його для досягнення кращої продуктивності.
Необхідно налаштувати систему моніторингу Zabbix або Grafana і слідкувати за показниками.
2. Розбити систему на частини і запускати їх окремо
Цей підхід передбачає окремий запуск функціональних частин системи:
- API,
- Адміністративної частини/ Армів,
- публічної частини
- мікро сервісів.
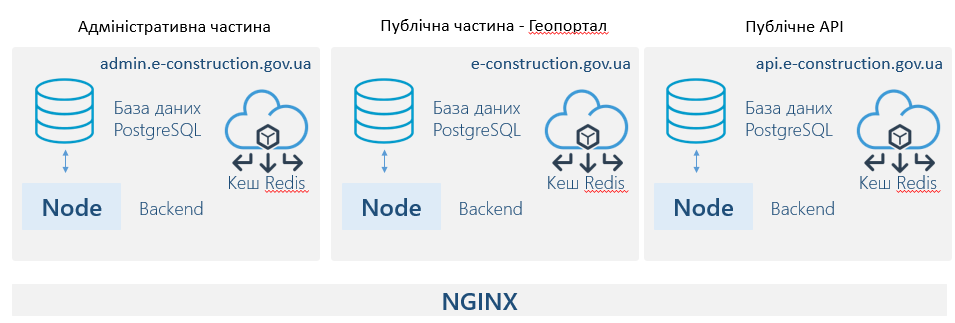
Це дозволяє ефективніше використовувати ресурси та розподіляти навантаження між серверами.
3. Кластерізація
За допомогою кластерізації можливо зробити кожен сервіс окремо, як представлено на схемі нижче.
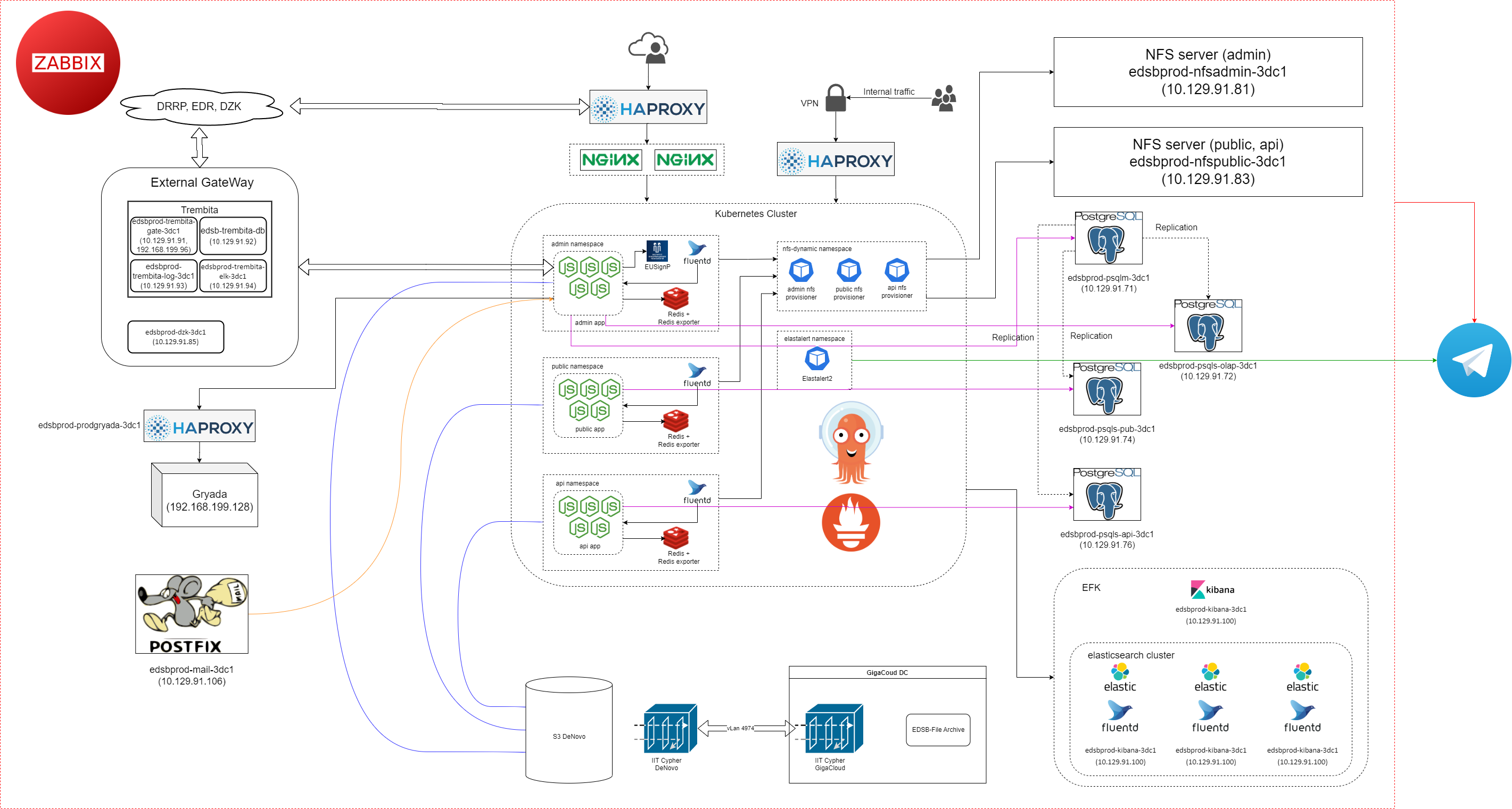
Кластерізація - це метод, який дозволяє розподілити навантаження та збільшити масштабованість системи шляхом об'єднання кількох серверів у групу, відому як кластер. Він надає більшу надійність, продуктивність та можливість масштабування системи.
PG cluster
В основі роботи Master - Slave - реплікація
- Всі транзакції/OLTP - запити на додавання зміну контенту пишуться в master. Такі запити швидкі їх меньше 10%
- Статистичні, аналітичні запити Olap - ідуть на slave. Таких запитів більше 90%
Налаштування:
{
"admin.edsb.local.ua": {
"project": [
"edesb"
],
"sid": 35,
"db": "master:pass@localhost:5432/geo_admin_dabi", // master db
"olap1": [
"olap:pass@localhost:5432/geo_admin_dabi" // olap db
]
}
}
Redis cluster
Redis Cluster - вбудована функція Redis, яка дозволяє розподілити дані та навантаження між кількома вузлами. Redis Cluster забезпечує горизонтальне масштабування, високу доступність та стійкість до відмов.
Redis Cluster використовує шарування даних, де ключі розподіляються між різними вузлами у кластері. Це дозволяє розділити навантаження на декілька серверів і обробляти запити паралельно, що підвищує продуктивність.
Основні особливості Redis Cluster:
- Шарування даних: Дані розділяються на декілька вузлів у кластері, що дозволяє балансувати навантаження та забезпечувати паралельну обробку запитів.
- Автоматичне реплікування: Redis Cluster забезпечує автоматичне реплікування даних між вузлами, що гарантує високу доступність та стійкість до відмов. Якщо один вузол виходить з ладу, дані автоматично реплікуються на інші вузли.
- Розподілена майстерність: Кожен вузол у Redis Cluster може бути майстром для певної частини даних і слейвом для інших частин. Це дозволяє розподіляти навантаження на запис та забезпечувати паралельну обробку.
- Автоматичне розпізнавання та відновлення: Redis Cluster має механізми для автоматичного розпізнавання вузлів та відновлення випадків відмов. Це забезпечує стійкість та безперервну роботу кластера.
Node Cluster
Варіанти: на одному сервері на різних портах або в кластерному режимі, на різних серверах
За допомогою PM2 в кластерному режимі
cd /data/softpro/server/node/ && \
pm2 start index.js -i <кількість_екземплярів>
замініть <кількість_екземплярів> на бажану кількість екземплярів, яку ви хочете запустити. PM2 автоматично розподілить навантаження між цими екземплярами.
На різних портах і серверах. Балансування навантаження за допомогою nginx:
Приклад config файлу.
upstream node_app {
server localhost:3000;
server localhost:3001;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://node_app;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Ви можете запустити кілька екземплярів вашої програми Node.js на різних портах або в різних контейнерах Docker.
Kubernetes. Автоматизоване масштабування
Це платформа для автоматизованого масштабування та управління контейнерами. Kubernetes дозволяє створювати кластери, управляти ними та автоматично масштабувати ресурси в залежності від навантаження. Він забезпечує автоматичну балансування навантаження та перенаправлення запитів на доступні сервери, що покращує продуктивність та надійність системи.
Опис процесу масштабування за допомогою Kubernetes:
- Налаштуйте кластер Kubernetes. (Потрібно налаштувати кластер Kubernetes, що складається з майстер-ноди та вузлів. Майстер-нода керує кластером, а вузли - це місце, де виконуються ваші контейнери).
- Cтворити конфігураційні файли. (Для масштабування ви маєте створити два типи файлів конфігурації: файл деплойменту та файл сервісу).
- Розгорнути деплоймент та сервіс. (Після створення конфігураційних файлів виконайте наступні команди, щоб розгорнути деплоймент та сервіс в кластері Kubernetes).